

[toc]
控制
条件码(condition code)
if-else, switch等条件判断语句,需要用到条件码寄存器来执行条件分支的指令.
条件寄存器的条件码:
- CF(carry flag):检测最高位产生进位,检测无符号数溢出
- ZF(zero flag):最近的操作结果为0
- OF(overflow flag):最近的操作导致补码溢出。
- SF(sign flag):最近操作结果为负数
设置条件码的指令:
- INC和DEC
- CMP
- TEST
cmp && test 指令
CMP S1, S2:计算S2 - S1
TEST S1, S2:计算S1 & S2
CMP和TEST指令,不会改变寄存器的值
test
testq:会将两个操作数按位与。
testq %rax, %rax # 将%rax按位与,结果还是%rax,但是会读取%rax的信息到寄存器根据EFLAGS寄存器中的信息就可以知道%rax中存储的数的性质了。
- ZF(零标志):如果结果是零,则设置 ZF;否则清除 ZF。
- SF(符号标志):如果结果的最高有效位(符号位)为 1,则设置 SF;否则清除 SF。
- OF(溢出标志):对于
testq指令,总是清除 OF,因为按位与操作不会引发溢出。 - CF(进位标志):对于
testq指令,总是清除 CF,因为按位与操作不会产生进位。 - PF(奇偶标志):根据结果的最低字节中 1 的数量是奇数还是偶数来设置或清除 PF。
在判断x > 0时,通过testq %rax, %rax,我们可以得到x的寄存器信息。
- 如果
%rax是正数,那么 ZF 被清除(ZF=0),SF 被清除(SF=0)。 - 如果
%rax是零,那么 ZF 被设置(ZF=1)。 - 如果
%rax是负数,那么 SF 被设置(SF=1),ZF 被清除(ZF=0)。
使用 jg(跳转如果大于)指令可以判断 %rax 是否大于零。 jg 指令依赖于 SF 和 ZF 标志:
jg(jump if greater)实际上是jnle(jump if not less or equal),即ZF=0且SF=OF。
访问条件码
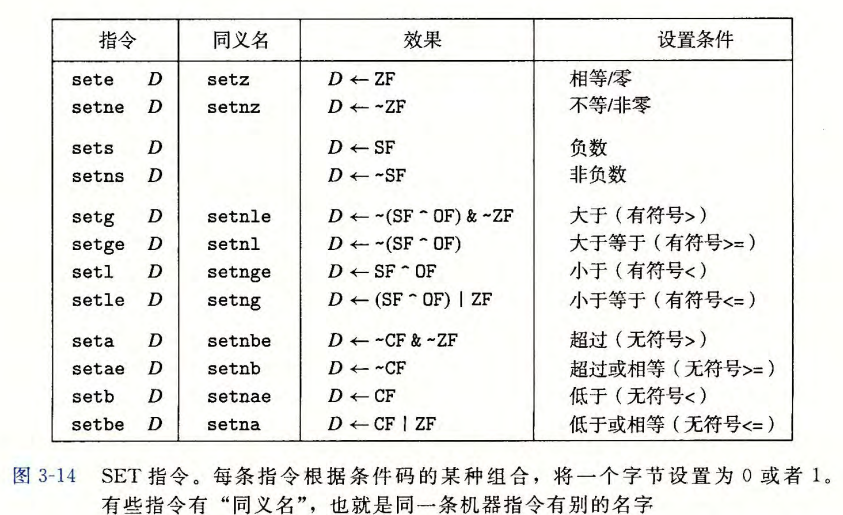
指令格式:[setxxx] D,将xxx寄存器的值,赋予D
sete/setz:相等时,赋予ZF给D
sets:结果为负数
setnx,表示结果取反
setg:有符号大于
setl:有符号小于
seta:无符号大于
setb:无符号小于
setxe,表示xx等于
条件分支的汇编代码

跳转指令
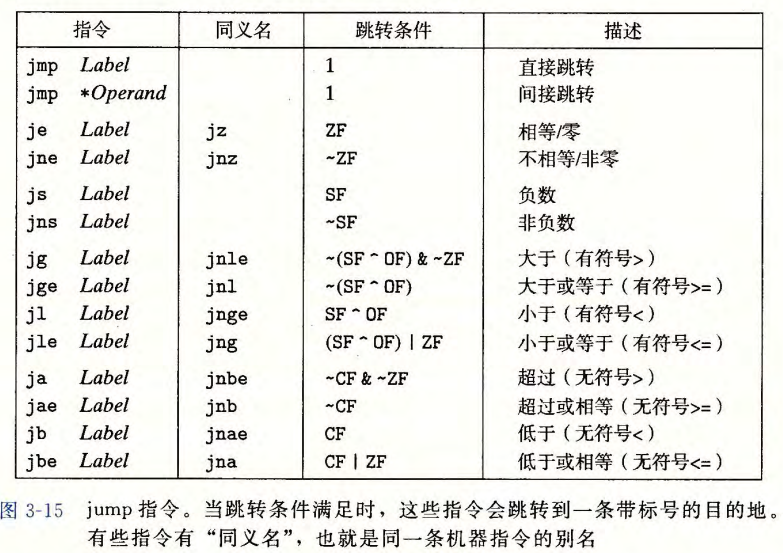
- 如:jg(jump greater):根据CMP(做减法)来进行比较,跳转的条件为
~(SF ^ OF) & ~ZF - CMP,表示前操作数 - 后操作数。jg满足一下两个条件
-
结果不为0,
-
结果为负数 xor 溢出
| SF | OF | ~(SF xor OF) | 说明 |
|---|---|---|---|
| 0 | 0 | 0 | 结果为正数,没溢出(结果没溢出,为正数) |
| 0 | 1 | 1 | 结果为正数,有溢出(下溢出) |
| 1 | 0 | 1 | 结果为负数,没有溢出 |
| 1 | 1 | 0 | 结果为负数,有溢出(结果为负数,往上溢出) |
反汇编代码的阅读
在执行PC的相对寻址时,PC的值指的是跳转指令后面那条指令的地址,而不是当前指令的地址。在加上当前指令中的偏移量,就可以得到跳转后的地址。

利用条件控制来实现条件分支
核心:通过一个判断来控制条件转移,两个不同条件的代码,只会执行其中一个分支。
如下代码:展示了如何将一个 复合的条件分支转化为汇编代码。
其中:布尔短路,就表现在在第一个条件控制代码中,(当p == null时,直接jp到 .L1)

利用条件传送来实现条件分支
核心:计算一个条件操作下的,两种结果代码,然后根据条件,来直接选择结果。(两个分支的代码都会执行,得到结果,然后再进行选择。)

基于条件数据传送的代码会比基于条件控制转移的代码性能比较
二者的区别,主要取决于现代处理器的流水线指令模式。CPU再执行运算前,需要执行以下5个阶段的操作。只有当CPU取指后,能够按照顺序不中断地执行下去,这样才能最好地发挥CPU的性能。
指令流水线的基本阶段
典型的指令流水线包括以下几个阶段:
- 取指(Fetch):从内存中取出指令。
- 译码(Decode):解析指令,确定操作类型和操作数。
- 执行(Execute):执行指令操作,例如算术运算或逻辑运算。
- 访存(Memory Access):访问内存操作数(如果需要)。
- 写回(Write Back):将结果写回寄存器或内存。
为了保证这一性能的高效性,现代CPU通常会采用某种方法来预测下一个跳转条件分支,从而实现指令执行的连续性。当预测错误之后,再重新取指,从头开始执行。(重新取指会导致CPU空闲,浪费性能)
-
对于基于条件控制的代码来说,当预测失败的时候,就需要进行重新取指,这就会导致CPU指令吞吐量低下。
-
对于基于条件数据传送的代码来说,会直接执行两个条件分支中的所有指令,然后再使用条件移动指令(如:cmov)来进行赋值。这不会中断流水线,因为它不会改变程序的控制流,不需要进行分支预测,清除和重新加载指令(条件移动指令的特性)。
条件传送指令
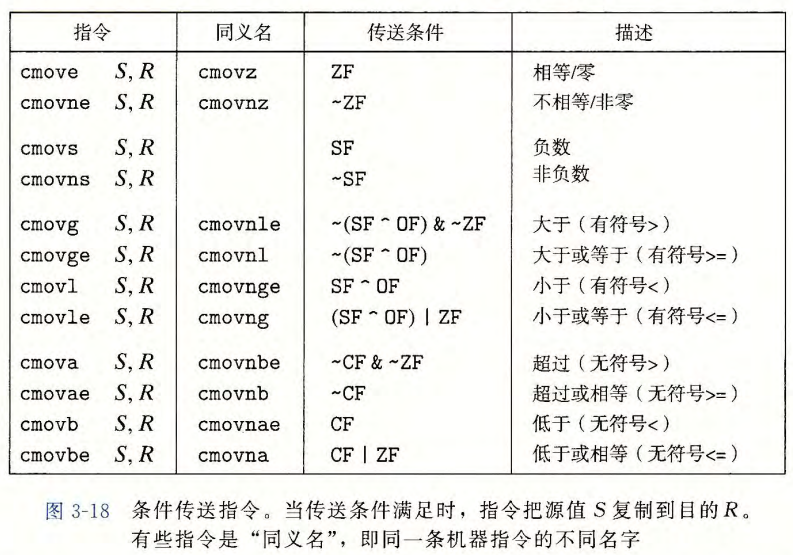
-
条件传送的误区:

即使当testq的测试为假时(%rdi为空指针),movq指令也会执行一次对%rdi的引用,任然会有空指针错误。
经验表明:GCC只有在两个条件分支的表达式都非常容易计算(如:都是一个加法运算)是,才会使用条件传送。
循环
对于循环,有两种翻译模式;第一种,do-while模式,第二种while(){do}模式(也叫做中间翻译模式,或者guarded-do)。
- do-while模式:先执行do的指令,随后按顺序执行到test指令进行判断。
do{ ....} while( test condition );对应的汇编代码:
loop: ... testq a, b jmp L1.L1. ... ret- while-do模式:翻译成汇编代码会在代码的开头跳转到条件判断指令,判断后再重新跳转到do的指令。
while( test condition ){ do...}对应的汇编代码:
loop: jmp .L1.L1 ...
.L2 testq a, b jmp L1. ret奇偶校验的循环
奇偶校验:统计数字中1的个数为奇数还是偶数,奇数返回1,偶数返回0.
通过把y = 0与x不断异或,并且x逐渐抛弃最低位,y的最低位,将存储与x中从低到高的每一位的异或结果。
最后通过y & 1得到y的最后一位。
long fun_a(unsigned long x) { unsigned long result = 0;
while (x != 0) { result ^= x; x >>= 1; }
return result & 1;}翻译成汇编代码如下:
fun_a(unsigned long): mov eax, 0 jmp .L2.L3: xor rax, rdi shr rdi.L2: test rdi, rdi jne .L3 and eax, 1 retfor循环
对于for循环,可以等价为以下的while循环模式
init-expr;while(test-expr){ body-statement; update-expr;}GCC翻译出的for循环汇编代码就是根据while的模板来实现的。
int res = 0;
void fun_while(int n){ int i = 0; while(i < n){ res++; i++; }}
void fun_for(int n){ for(int i = 0; i < n; i++){ res++; }}对应的汇编代码:
fun_while(int): mov eax, 0 jmp .L2.L3: add DWORD PTR res[rip], 1 add eax, 1.L2: cmp eax, edi jl .L3 ret
fun_for(int): mov eax, 0 jmp .L5.L6: add DWORD PTR res[rip], 1 add eax, 1.L5: cmp eax, edi jl .L6 retres: .zero 4continue
int res = 0;
void fun_while(int n){ int i = 0; while(i < n){ if(i == 1){ continue; } res++; i++; }}对于增加了continue的代码,我们不能再使用do-guarded模式翻译的while循环代码了。
fun_while(int): mov eax, 0.L2: cmp eax, edi # 每次开头测试 jge .L5 cmp eax, 1 je .L2 # continue变为一个jump命令 add DWORD PTR res[rip], 1 add eax, 1 jmp .L2.L5: ret # L5直接结束循环res: .zero 4# 更直白的写法。fun_while(int): mov eax, 0 jmp .L2.L3: cmp eax, 1 je .L2 # continue变为一个jump命令 add DWORD PTR res[rip], 1 add eax, 1.L2: cmp eax, edi jl .L3 ret- 上一种汇编写法是优化后的版本
- 减少了循环开头的指令跳转
- 简化了指令标签的数量,使得汇编代码更加简洁。
switch语句
switch语句根据一个整数索引值来跳转到多重分支。
通过使用跳转表(jump table)(数组)来实现,不同的索引项i,内部保存了代码段的地址。因此在大量情况的条件下,使用switch的性能大于if-else.
注:在case 语句中,如果没有写入break语句。在翻译出的汇编代码中就会存在同一个指令标签中,因此会连续执行。
int fun_while(int n){ int i = 0; switch(n){ case 1: i += 1; break; case 2: i += 2; //没有break case 3: i += 3; break; case 4: i += 4; break; default: i += 0; break; } return i;}注意:翻译成汇编语言后,cmp指令中,对应的常数为switch table中的索引,而不是case中n的值。
fun_while(int): cmp edi, 3 # %edi中保存着jump table的索引。 je .L5 cmp edi, 3 jg .L3 cmp edi, 1 je .L6 cmp edi, 2 je .L2 mov eax, 0 ret.L3: cmp edi, 4 jne .L7 mov eax, edi ret.L5: mov edi, 0.L2: lea eax, [rdi+3] ret.L6: mov eax, edi ret.L7: mov eax, 0 ret跳转表的形式:(CSAPP书中的例子)
